

Do you have to click on all the motorcycle bits?
A petty but sincere investigation into CAPTCHAs.

Have you ever gotten stuck on a stupid little captcha? You know, the kind that asks you to select the cells with the motorcycle — except there’s a tiny bit of the motorcycle that’s out of the main cell. Should you click it or not?
At first, you decide not to, because that’s what smart people do. But then you fail the captcha, so you try again on the next slide. This time it’s traffic lights. And you select the itsy-bitsy bit that sticks out of the main box…
And you fail again. Why? Are CAPTCHAs just badly designed? Am I just bad at them? Somehow my mom never gets stuck (and she’s not good with tech), so what’s the trick?

A long time ago in a galaxy far, far away, you squinted at distorted text
Before the motorcycles and traffic lights, there were squiggly letters.
By the early 2000s, the internet was shifting from a nerd playground to something more mainstream. Normal people were signing up for email accounts, leaving comments, joining forums. And with them came spam — lots of it. Bots flooded sign-up forms, scraped data, posted junk links, and overloaded forums with scams and nonsense. It wasn’t just annoying; it could bring down entire sites. Web services needed a way to separate humans from scripts — quickly.

The original CAPTCHA was simple: show users a warped mess of letters and numbers, and ask them to type it in. A digital eye test of sorts. It worked because bots couldn’t read – at this time, machine vision was all but a scifi dream. To bots, a distorted “g” might as well have been a Jackson Pollock.
These tests spread fast. Yahoo, Google, MSN, — everyone slapped CAPTCHAs onto their forms. The word CAPTCHA itself became the catch-all term1. It wasn’t user-friendly — even humans struggled to read the mess — but it worked well enough.
Your Civic Duty: Typing “Participated” into a Box
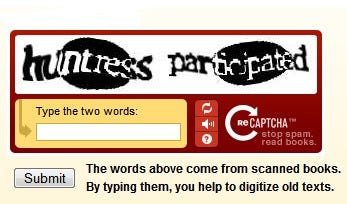
By 2007, the text-based CAPTCHA got a small upgrade. Instead of random squiggles, it started pulling real words from scanned books — fragments that OCR2 software couldn’t read. Ink smears, crooked printing, faded letters. Too messy for machines, but still legible to humans.
That was the premise of reCAPTCHA. It looked like a normal challenge, but behind the scenes, users were helping digitize old books and newspapers. One word in the test was already known — it was just checking if you were human. The other word was unknown. That was the real goal: get millions of people to transcribe it. In 2010, it’s estimated that 100 million CAPTCHAs were completed every single day.
Most users didn’t realize they only needed to get one word right — they just tried to do both. Which, of course, was exactly the point.
And naturally, the bots got better. Of course they did — we were the ones training them. Every time someone typed in a blurry word, it became another labeled datapoint for OCR. After years of this, machines started beating us at our own test. So text CAPTCHAs had to go. The future needed images.
How the “dog” caught the “car”
Once bots learned to read, we moved on — because nothing can stop progress, not even the bots we’re trying to stop. In the early 2010s, CAPTCHAs started showing image grids instead — blurry pictures of pets, food, storefronts, street signs. You’d be asked to click all the chimneys, or all the tennis balls.
This wasn’t just about keeping bots out anymore. The OCR trick had worked so well, big tech recycled the formula — this time to train computer vision. Early image CAPTCHAs like Asirra asked users to distinguish cats from dogs. It was simple, effective, and gave researchers a goldmine of labeled data. At launch, humans passed it 99% of the time. Bots had no chance. But that didn’t last: within a year, researchers had trained models that could solve it 10% of the time. But at scale, “barely good enough” is all you need to cause damage.
Since 2012, Google has leaned hard into visual grids: crosswalks, buses, fire hydrants. Not coincidentally, the same things their self-driving car project needed help with. Every click on a blurry stop sign becomes training data for a neural net behind the scenes.
So now, here we are – staring at a little square. A sliver of a traffic light poking in. Should you click it?

The arms race of getting all your data
By now, the image itself is a decoy — a user-friendly wrapper for what’s really going on. What determines whether you pass a CAPTCHA isn’t what you click, but how you click it. Mouse movement, hover time, typing rhythm. Google’s reCAPTCHA doesn’t just ask if you’re a human — it watches you act like one. And if your setup looks too clean, too fast, or too private… well, that’s suspicious.
This is why you can click the square with the tiny sliver of traffic light — or not — and still pass. There’s no correct answer. It’s not about accuracy; it’s about probability. You just have to act enough like a human, on a device that acts enough like everyone else’s.
And if that sounds a little shady... well, it is. Google’s reCAPTCHA v3 is entirely invisible — no checkbox, no challenge. It runs in the background, collecting behavioral signals and browser data, scoring how likely you are to be a bot.
This 2023 study found that all current CAPTCHA challenges not only cost users a lot of time, they discriminate based on education, and worse still, they are useless to combat bots.3 Modern spam systems run circles around them. For example, OpenAI’s ChatGPT can solve all variations of them, which is what allows for the “search the internet” capability. Funnily enough, they use CAPTCHAs themselves as anti-bot prevention.4 But the grid puzzles stick around not because they work as gatekeepers, but because they work beautifully as data funnels.
And you know what? That tiny square with the sliver of traffic light? Click it. Don’t click it. It doesn’t really matter. Just move your mouse like you mean it – and be a good little product they can harvest.
So… what now?
So, if you’ve been failing CAPTCHAs to the point of losing your mind — congrats. That probably means you’ve managed to make your browser just private enough to be suspicious. Honestly, I respect it. Keep going.
That said… I’ve eased up on my own adblockers. Not because I’ve stopped caring about privacy, but because, well, I need to get through forms without doing six rounds of traffic lights. I’m all for giving Big Tech the middle finger — but I’d also like to browse in peace.
So my work laptop? Wide open. No shields. No blockers. It’s not really mine anyway. I don’t do anything personal on there. It’s already compromised by design — might as well let the bots think I’m the most average, compliant human on earth. My personal laptop is still a bit more secure, but I don’t block all cookies as I used to, just enough so I can browse in peace (which is worse: endless captchas or 5 pop-ups?).
If this all feels a little more twisted than you expected… yeah. Same here.
Want to read more from me? Here are 3 pieces I think you’ll enjoy:
How to not vibecode yourself in the foot, or some advice as a software engineer so that you don’t regret using AI to code
There is no TV inside my mind, about my experience with aphantasia (i can’t see shit when i close my eyes)
Dreaming up the threats of the future (on the French army’s payroll), about that time we the French paid scifi writers a fuck ton to imagine all the dangers we’ll face in the 2030s
Thank you for reading and see you next time! The next post will probably be about Severance (i know, shoring up after the storm) and more specifically the character of Gretchen. Putting that here in case you’re reading, so that you hold me accountable :)
edit: well I ended up switching the order of those posts, so you can read the Gretchen piece here <3
Thank you to everyone who helped me edit or encouraged me to write this post: Michelle Elisabeth Varghese, Matt Cyr, LaLa ✿Indie Maker✿, Simon Emslie, Clo.
“Completely Automated Public Turing test to tell Computers and Humans Apart” – it’s as if they were trying to make it as clunky as possible
Optical Character Recognition, ie software that lets computers read text from pictures
Other systems have been made to combat them anyways, and they work a lot better
CAPTCHAs are in part the reason why it’s so slow: ChatGPT has to pretend to be human when it’s looking up something, which includes slow response times.
I want to say I’m glad you wrote this and I found it so fascinating! I had heard the words were used to train data and I always wondered if I was training a model with the images. I can’t believe it’s not about the actual answer, that’s surprising to me. I also like to have my data private so maybe no surprise I fail these so often (it’s not me!) I’m glad you turned your own rabbit hole into an essay
Really insightful! I never dug into how the captchas work and I also didn’t realise they’re google’s, so I might go around do some sleuthing to see the backend haha